
'll Hacker
[ML 실습] 12일차 복습 - 분류 성능평가 지표: 오차행렬 본문
앞 시간에는 정확도에 대해서 설명했었다. 정확도는 데이터의 어떠한 특징때문에 신중히 사용해야된다는 것을 알았다.
그래서 정확도말고 다른 성능평가 지표도 소개할 것이다. 이번 시간에는 오차행렬(Confusion matrix)에 대해서 소개하겠다.
Confusion Matrix
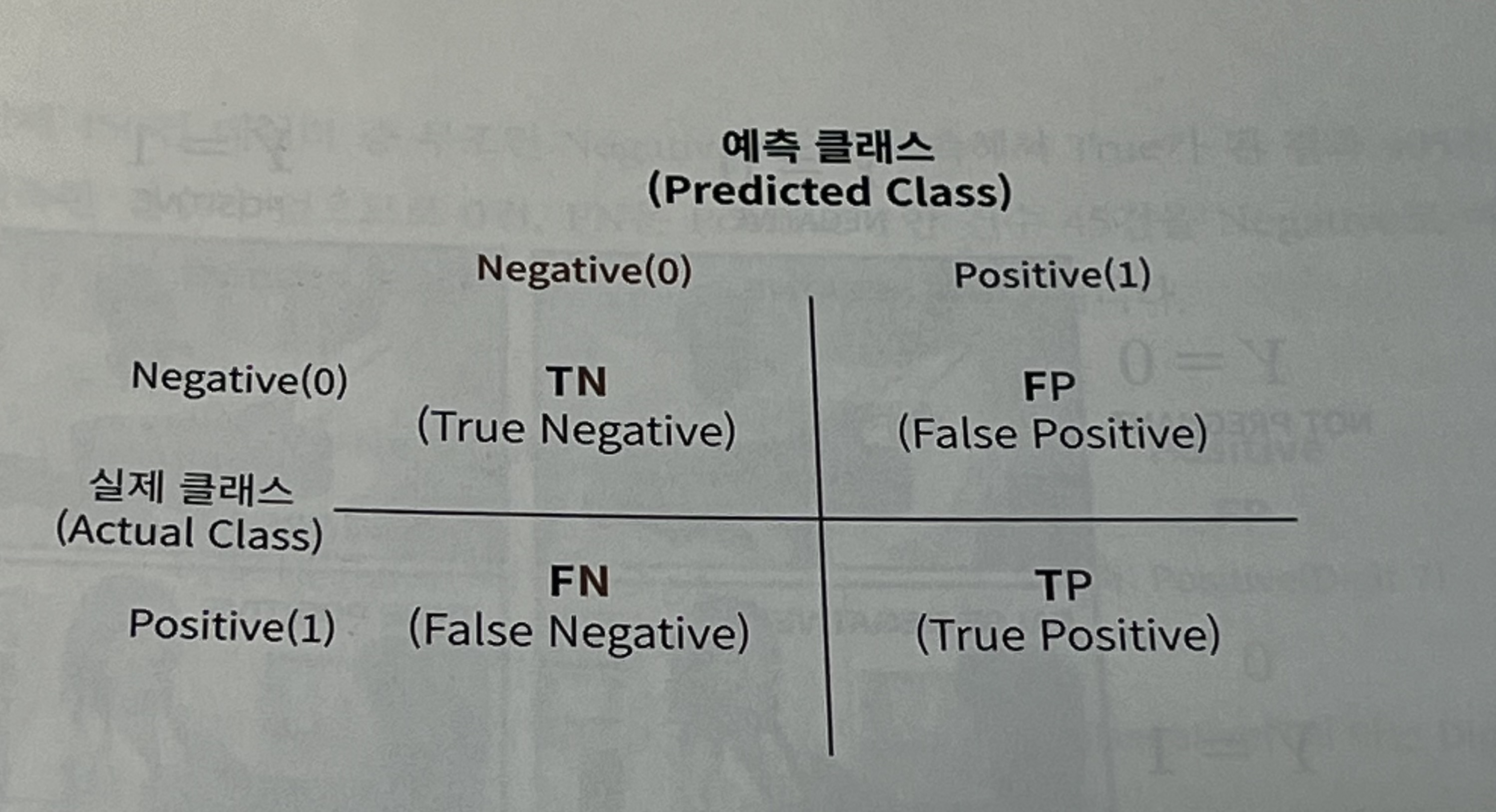
4분면이 있고, 실제 레이블 클래스 값과 예측 레이블 클래스 값이 어떠한 유형을 가지고 매핑되는지를 나타낸다.
TN부터, True Negative로 앞 True는 실제값과 예측값이 같다는 의미이고, Negative는 예측값이 Negative라는 의미이다. 즉, TN은 예측을 Negative값 0으로 예측했는데, 실제 값도 Negative값 0이라는 의미이다.
앞에 정확도 예제에서 다룬 MyFakeClassifier의 예측 성능 지표를 Confusion Matrix로도 나타내보자.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, fakepred)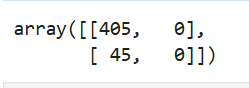
이 결과를 보면 예측값이 Negative(7이 아닌 Digit)이고, 실제값과 동일한 것이 405개, 예측값이 Positive(7인 Digit)이고 실제값과 다른 것이 0개, 예측값이 Negative(7이 아닌 Digit)이고, 실제값과 다른 것이 45개, 예측값이 Positive(7인 Digit)이고 실제값과 동일한 것이 0개 이다.
이 값을 조합해 Classifier의 성능을 측정할 수 있는 주요 지표들의 값들도 알 수 있다.
정확도는 예측값과 실제값이 얼마나 동일한가에 대한 비율만으로 결정된다. Confusion Matrix에서 True에 해당하는 값인 TN과 TP에 좌우된다. 정확도는 Confusion Matrix로 나타내면 (TN+TP) / (TN+FP+FN+TP)이다.
일반적으로 이러한 불균형한 레이블 클래스를 가지는 이진 분류 모델에서는 많은 데이터 중에서 중점적으로 찾아야 하는 매우 적은 수의 결괏값에 Positive를 설정해 1값을 부여하고, 그렇지 않은 경우는 Negative로 0값을 부여하는 경우가 많다고 한다.
불균형한 이진 분류 데이터 세트에서는 Positive 데이터 건수가 매우 작기 때문에 데이터에 기반한 ML 알고리즘은 Positive보다는 Negative로 예측정확도가 높아진다고 한다. 9900건이 Negative이고, 100건이 Positive라면 Negative로 예측하는 경향이 더 강해져서 TN은 매우 커지고 TP는 매우 작아지게 된다. 또한 Negative로 예측할 때 정확도가 높기 때문에 FN이 매우 작고, Positive로 예측하는 경우가 작기 떄문에 FP도 매우 작아지게 된다. 결과적으로 정확도 지표는 비대칭한 데이터 셋에서 Positive에 대한 예측 정확도를 판단하지 못한 채 Negative에 대한 예측 정확도만으로도 분류의 정확도 매우 높게 나타나는 수치적인 판단 오류를 일으키게 된다.
다음은 불규형한 데이터 셋에서 정확도보다 더 선호되는 평가 지표인 정밀도와 재현율을 소개하겠다.
'AI > 머신러닝' 카테고리의 다른 글
| [ML 실습] 13일차 복습 - 분류 성능평가 지표: 정밀도와 재현율 (0) | 2025.11.16 |
|---|---|
| [ML 실습] 11일차 복습 - 분류 성능평가 지표: 정확도 (0) | 2025.11.15 |
| [ML 실습] 10일차 복습- 사이킷런으로 타이타닉 생존자 예측모델 만들기(Kaggle) (0) | 2025.03.23 |
| [ML 실습] 9일차 복습- 사이킷런 머신러닝 만들어보기(데이터 전처리) (0) | 2025.03.17 |
| [ML 실습] 8일차 복습- 사이킷런 기반 FrameWork 익히기 (1) | 2025.03.12 |

