
'll Hacker
[ML 실습] 1일차 복습- 넘파이 ndarray 본문
위 블로그는 공부 목적으로 기록한 블로그입니다. (책 광고x)
NumPy 개요.
넘파이는 Numerical Python을 의미함.
파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있는 패키지이다.
루프를 사용하지 않고, 대량 데이터의 배열 연산 가능 -> 빠른 속도 연산 처리가 가능하다.
C/C++ 기반의 코드로 작성하고 이를 넘파이에서 호출하는 방식으로 쉽게 통합가능
구글의 대표적인 딥러닝 프레임워크인 텐서플로는 배열 연산 수행 속도를 개선하고 넘파이와 호환할 수 있다.
import numpy as np⏫넘파이 모듈 임포트
넘파이 기반 데이터 타입 : ndarray
넘파이에서 다차원 배열을 쉽게 생성하고 다양한 연산 수행할 수 있음.
1. array( ) 함수
array1 = np.array([1,2,3])
print('array1 type: ', type(array1))
print('array1 array 형태: ', array1.shape)
array2 = np.array([[1,2,3],[2,3,4]])
print('array2 type: ',type(array2))
print('array2 array 형태: ', array2.shape)
array3 = np.array([[1,2,3]])
print('array3 type: ', type(array3))
print('array3 array 형태: ', array3.shape)파이썬의 리스트와 같은 다양한 인자를 입력받아서 ndarray로 변환하는 기능이다.
생성된 ndarray 배열의 shape 변수는 행과 열의 수를 튜플 형태로 가지고 있고, ndarray배열의 차원도 알 수 있다.

array1과 array3의 차이점을 이해하는 것은 중요한 것 같다.
array1은 [1,2,3]으로 array()의 인자값으로 되어 있고, array3은 [[1,2,3]]으로 되어있다.
array1은 1차원 array로 3개의 데이터를 가지고 있음.
array3은 2차원 array로 3개의 데이터를 가지고 있음. 이 둘 차이는 차원이다.
중요한 이유는 머신러닝 알고리즘과 데이터 세트 간의 입출력과 변환을 수행하다보면 명확히 1차원 데이터 또는 다차원 데이터를 요구하는 경우가 많다고 한다.
print('array1: {0}차원, array2: {1}차원, array3: {2}차원'.format(array1.ndim, array2.ndim, array3.ndim))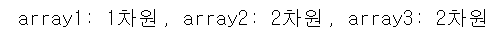
array( ) 함수의 인자로는 파이썬의 리스트 객체가 주로 사용됨.
array.ndim = 배열의 차원 수
array.shape = 배열 각 차원의 크기를 튜플 형태로 표현함. n행 m열의 행렬의 경우 (n,m) 형태의 튜플로 나타냄.
array.dtype = 데이터 타입 표현
array.itemsize = 배열의 각 요소의 바이트 단위로 크기를 표현
array.data = 배열의 데이터가 메모리의 어느 위치에 저장되어있는지 알려줌.
list1 = [1,2,3]
print(type(list1))
array1 = np.array(list1)
print(type(array1))
print(array1, array1.dtype)ndarray 내의 데이터값은 숫자값, 문자열값, 불 값 등 모두 가능. 하지만, 같은 데이터만 가능.

list2 = [1,2,'test']
array2 = np.array(list2)
print(type(array2))
print(array2,array2.dtype)
list3 = [1,2,3.0]
array3 = np.array(list3)
print(array3, array3.dtype)
다른 데이터 타입이 섞여있다면 데이터 크기가 더 큰 데이터 타입으로 형변환을 한다.
위 결과를 보면, 1,2,'test'가 있는데 문자열이 데이터 크기가 크므로 정수형 1, 2 이인데도, 문자열로 결과출력되어있다.
두 번째 예시에도 마찮가지로 1, 2, 3.0 중에서 3.0인 실수형이 데이터 크기가 크므로 정수형 1, 2 도 실수형으로 변환되어서 출력되었다.
dtype은 ndarray의 데이터 타입을 출력할 수 있는 객체 속성이다.
2. astype( ) 함수
array_int = np.array([1,2,3])
array_float = array_int.astype('float64')
print(array_float, array_float.dtype)
array_int1 = array_float.astype('int32')
print(array_int1, array_int1.dtype)
array_float1 = np.array([1.1,2.1,3.1])
array_int2 = array_float1.astype('int32')
print(array_int2, array_int2.dtype)ndarray 내 데이터 값의 타입변경할 수 있는 메서드이다.
대용량 데이터의 ndarray를 만들 때 많은 메모리가 사용되는데, 메모리를 절약해야 할 때 이용된다.
대체적으로 파이썬 기반의 ML algorithm은 메모리로 데이터를 전체 로딩한 다음 이를 기반으로 알고리즘을 적용하기 때문에 대용량의 데이터를 로딩할 때는 수행속도가 느려지거나 메모리 부족으로 오류가 발생할 수 있다. 이럴 때 이용된다.
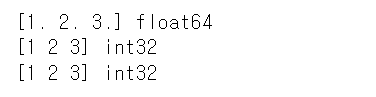
3. arang( ) 함수
sequence_array = np.arange(10)
print(sequence_array)
print(sequence_array.dtype, sequence_array.shape)array를 range( )로 표현하는 것.
파이썬 표준 함수인 range( )와 유사한 기능을 한다.
0 ~ 함수인자값-1 까지 값을 순차적으로 ndarray의 데이터값으로 변환해준다.
위에서와 같이 10이라고 하면 0~9까지인 것이다.
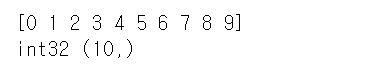
4. zeros( ) 함수
zero_array = np.zeros((3,2), dtype = 'int32')
print(zero_array)
print(zero_array.dtype, zero_array.shape)함수 인자로 튜플 형태의 shape 값을 입력하면 모든 값을 0으로 채운 해당 shape를 가진 ndarray를 반환
함수 인자로 dtype을 정해주지 않으면 default로 float64형의 데이터로 ndarray를 채운다.

5. ones( ) 함수
one_array = np.ones((3,2))
print(one_array)
print(one_array.dtype, one_array.shape)함수 인자로 튜플 형태의 shape 값을 입력하면 모든 값을 1로 채운 해당 shape를 가진 ndarray를 반환
함수 인자로 dtype을 정해주지 않으면 default로 float64형의 데이터로 ndarray를 채운다.

6. reshape( ) 함수
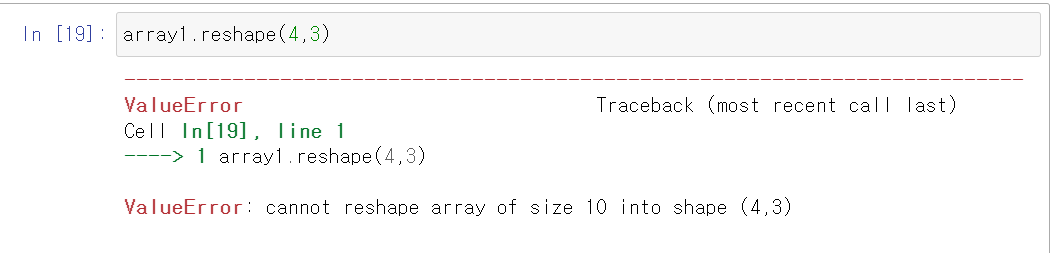
array1 = np.arange(10)
print('array1:\n', array1)
# array1:
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
array2 = array1.reshape(2,5) # array1의 차원을 변경
print('array2:\n',array2)
# array2:
# [0, 1, 2, 3, 4]
# [5, 6, 7, 8, 9]
array3 = array1.reshape(5,2) # array1의 차원을 변경
print('array3:\n',array3)
# array3:
# [0, 1]
# [2, 3]
# [4, 5]
# [6, 7]
# [8, 9]reshape( ) 메서드를 ndarray를 특정 차원 및 크기로 반환함

하지만,, 이것도 주의해서 사용해야된다.
array1 = np.arange(10)
print(array1)
array2 = array1.reshape(-1, 5)
print('array2 shape: ', array2.shape)
array3 = array1.reshape(5,-1)
print('array3 shape: ', array3.shape)'-1'을 인자로 사용하면 원래 ndarray와 호환되는 새로운 shape로 변환해줌.
array1과 호환되는 2차원 ndarray로 변환하되, 고정된 5개의 칼럼에 맞는 행을 자동으로 새롭게 생성해 변환가능.

reshape(-1,1)의 형태는 원본 ndarray가 어떤 형태라도 2차원이고,
여러개의 행을 가지되 반드시 1개의 칼럼을 가진 ndarray로 변환됨.

# reshape(-1,1)을 사용하여 3차원을 2차원으로, 1차원을 2차원으로 변경함
array1 = np.arange(8)
array3d = array1.reshape((2,2,2))
print('array3d:\n',array3d.tolist())
# 3차원 ndarray를 2차원 ndarray로 변환
array5 = array3d.reshape(-1,1)
print('array5:\n',array5.tolist())
print('array5 shape:',array5.shape)
# 1차원 ndarray를 2차원 ndarray로 변환
array6 = array1.reshape(-1,1)
print('array6:\n', array6.tolist())
print('array6 shape:', array6.shape)tolist는 array를 python의 리스트로 바꿔줌.
List vs array
배열은 선언되어야 하지만 / 리스트는 안그래도 됨.
배열은 array 모듈이나 numpy를 이용하지만 / 리스트는 대괄호로 원소들을 감싸주기만 하면됨
배열은 데이터를 메모리에 조밀하게 저장가능하지만 / 리스트는 쉬운 원소 추가를 위해 큰 메모리가 필요하다
배열은 한 원소에 대해 추가, 삭제, 업데이트를 하기 어렵지만 / 리스트는 쉽다
배열은 사칙연산에 뛰어나지만 / 리스트는 직접적으로 수학적 연산이 안된다
배열은 모든 원소가 같은 크기를 가져야한다. / 리스트는 리스트 안에 중첩이 가능하다.
참고 서적: 파이썬 머신러닝 완벽 가이드, 권철민, 위키북스
https://chancoding.tistory.com/11
'AI > 머신러닝' 카테고리의 다른 글
| [ML 실습] 4일차 복습- 판다스 DataFrame(1) (0) | 2025.01.28 |
|---|---|
| [ML 실습] 3일차 복습- 넘파이 마지막, 판다스 시작 (1) | 2025.01.27 |
| [LG AImers 6기] ML이론 - Bias and Variance (3) | 2025.01.23 |
| [LG AImers 6기] ML이론 - Introduction to ML (3) | 2025.01.21 |
| [ML 실습] 2일차 복습- 넘파이 ndarray 인덱싱 (0) | 2025.01.18 |



