
'll Hacker
[ML 실습] 2일차 복습- 넘파이 ndarray 인덱싱 본문
인덱싱은 넘파이에서 ndarray 내의 일부 데이터 세트나 특정 데이터만을 선택할 수 있도록 한다.
- 특정한 데이터만 추출
- Slicing
- Fancy Indexing
- Boolean Indexing
단일 값 추출 ▶️ 한 개의 데이터만 추출하는 방법
1개의 데이터값을 선택하려면 ndarray 객체에 해당하는 위치의 인덱스 값을 [ ]안에 입력하기
# 1부터 9까지의 1차원 ndarray 생성
array1 = np.arange(start=1, stop=10)
print('array1:',array1)
value = array1[2]
print('value:',value)
print(type(value))인덱스는 0부터 시작해서
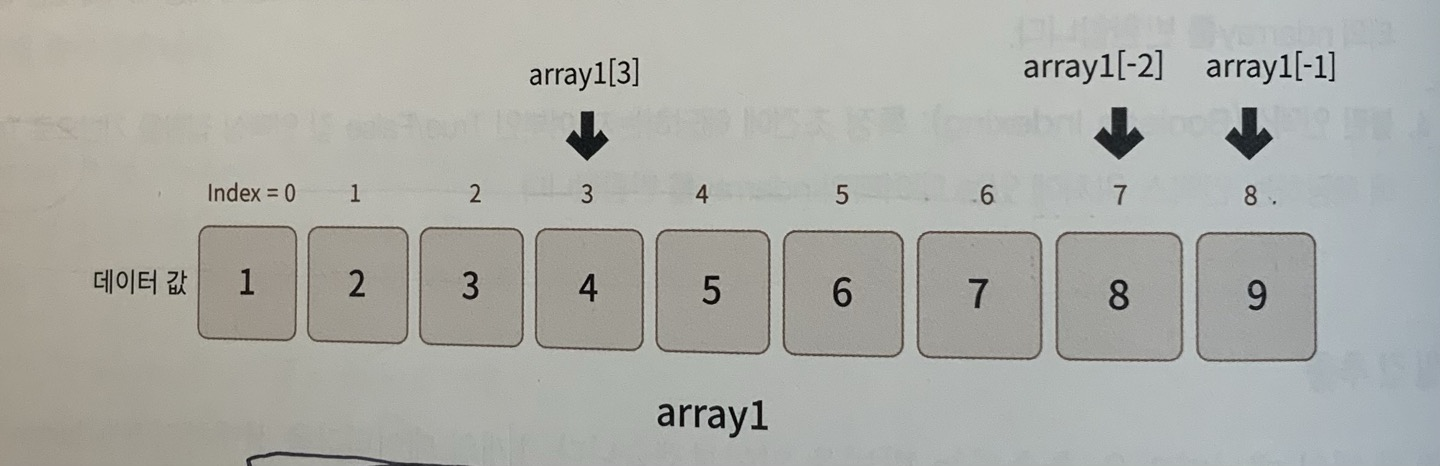
array1[2]은 3번째 인덱스 위치의 데이터값을 의미함. array1[2]은 ndarray 내의 데이터값을 의미한다.

print('맨 뒤의 값: ', array1[-1],'맨 뒤에서 두 번째 값:',array1[-2])인덱스에 마이너스 기호를 이용하면 맨 뒤에서부터 데이터를 추출가능
[-1]은 맨 뒤의 데이터값을 의미함.

| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 반대인덱스 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
| 데이터값 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
print(array1)
array1[0] = 9
array1[8] = 0
print('array1: ',array1)단일 인덱스를 이용해 ndarray 내의 데이터값도 간단히 수정가능

array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3,3)
print(array2d)
print('(row=0, col=0) index 가리키는 값: ', array2d[0,0])
print('(row=0, col=1) index 가리키는 값: ', array2d[0,1])
print('(row=1, col=0) index 가리키는 값: ', array2d[1,0])
print('(row=2, col=2) index 가리키는 값: ', array2d[2,2])

슬라이싱▶️ ' : ' 기호를 이용해 연속한 데이터를 슬라이싱해서 추출가능
array1 = np.arange(start=1, stop=10)
array3 = array1[0:3]
print(array3)
print(type(array3))' : ' 기호를 이용해 연속한 데이터를 슬라이싱해서 추출가능
' : ' 사이에 시작 인덱스와 종료 인덱스를 표시하면 시작 인덱스에서 종료인덱스-1의 위치에 있는 데이터의 ndarray를 반환함.
여기서는 [0:3]이니까 0~2의 위치에 있는 데이터의 ndarray를 반환한다.

array1 = np.arange(start=0, stop=3)
array4 = array1[:2]
print(array4)
array5 = array1[1:]
print(array5)
array6 = array1[:]
print(array6)' : ' 기호 앞에 시작 인덱스를 생략하면 자동으로 맨 처음 인덱스인 0으로 간주함.
' : ' 기호 뒤에 종료 인덱스를 생략하면 자동으로 맨 마지막 인덱스로 간주함
' : ' 기호 앞/뒤에 시작/종료 인덱스를 생략하면 자동으로 맨 처음/맨 마지막 인덱스로 간주함.

array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3,3)
print('array2d:\n', array2d)
print('array2d[0:2, 0:2]\n',array2d[0:2, 0:2])
print('array2d[1:3, 0:3]\n',array2d[1:3, 0:3])
print('array2d[1:3, :]\n', array2d[1:3, :])
print('array2d[:,:]\n',array2d[:,:])
print('array2d[:2,1:]\n',array2d[:2,1:])
print('array2d[:2, 0]\n',array2d[:2,0])
print(array2d[0])
print(array2d[1])
print('array2d[0] shape:',array2d[0].shape, 'array2d[1].shape:',array2d[1].shape)
팬시 인덱싱▶️리스트나 ndarray로 인덱스 집합을 지정하면 해당 위치의 인덱스에 해당하는 ndarray를 반환하는 인덱싱 방식
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3,3)
array3 = array2d[[0,1],2]
print('array2d[[0,1],2] =>',array3.tolist())
array4 = array2d[[0,1],0:2]
print('array2d[[0,1],2] =>',array4.tolist())
array5 = array2d[[0,1]]
print('array2d[[0,1]]=>',array5.tolist())[?1, ?2] 이라고 했을 때,
?1은 행에 대한 정의이고, ?2은 열에 대한 정의이다.

불린 인덱싱▶️조건 필터링과 검색을 동시에 할 수 있음.
array1d = np.arange(start=1, stop=10)
array3 = array1d[array1d>5]
print('array1d > 5 불린 인덱싱 결과 값:', array3)1차원 ndarray [1,2,3,4,5,6,7,8,9]에서 데이터값이 5보다 큰 데이터만 추출

array1d > 5
5보다 큰 데이터가 있는 위치는 True값이, 그렇지 않는 경우는 False값이 반환됨을 확인할 수 있음.
조건으로 반환된 이 ndarray 객체를 인덱싱을 지정하는 [ ]내에 입력하면 False값은 무시하고 True값이 있는 위치 인덱스 값으로 자동 변환해 해당하는 인덱스 위치의 데이터만 반환하게 됨.
즉, array([False, False, False, False, False, True, True, True, True])에서 False가 있는 인덱스 0~4는 무시하고 인덱스 [5,6,7,8]이 만들어지고 이 위치 인덱스에 해당하는 데이터 세트 [6,7,8,9]를 반환하게 됨.
boolean_indexes = np.array([False, False, False, False, False, True, True, True, True])
array3 = array1d[boolean_indexes]
print('불린 인덱스로 필터링 결과:', array3)
indexes = np.array([5,6,7,8])
array4 = array1d[indexes]
print('일반 인덱스로 필터링 결과:', array4)
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 데이터값 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
array1d[5], array1d[6], array1d[7], array1d[8] => [ 6, 7, 8, 9 ]
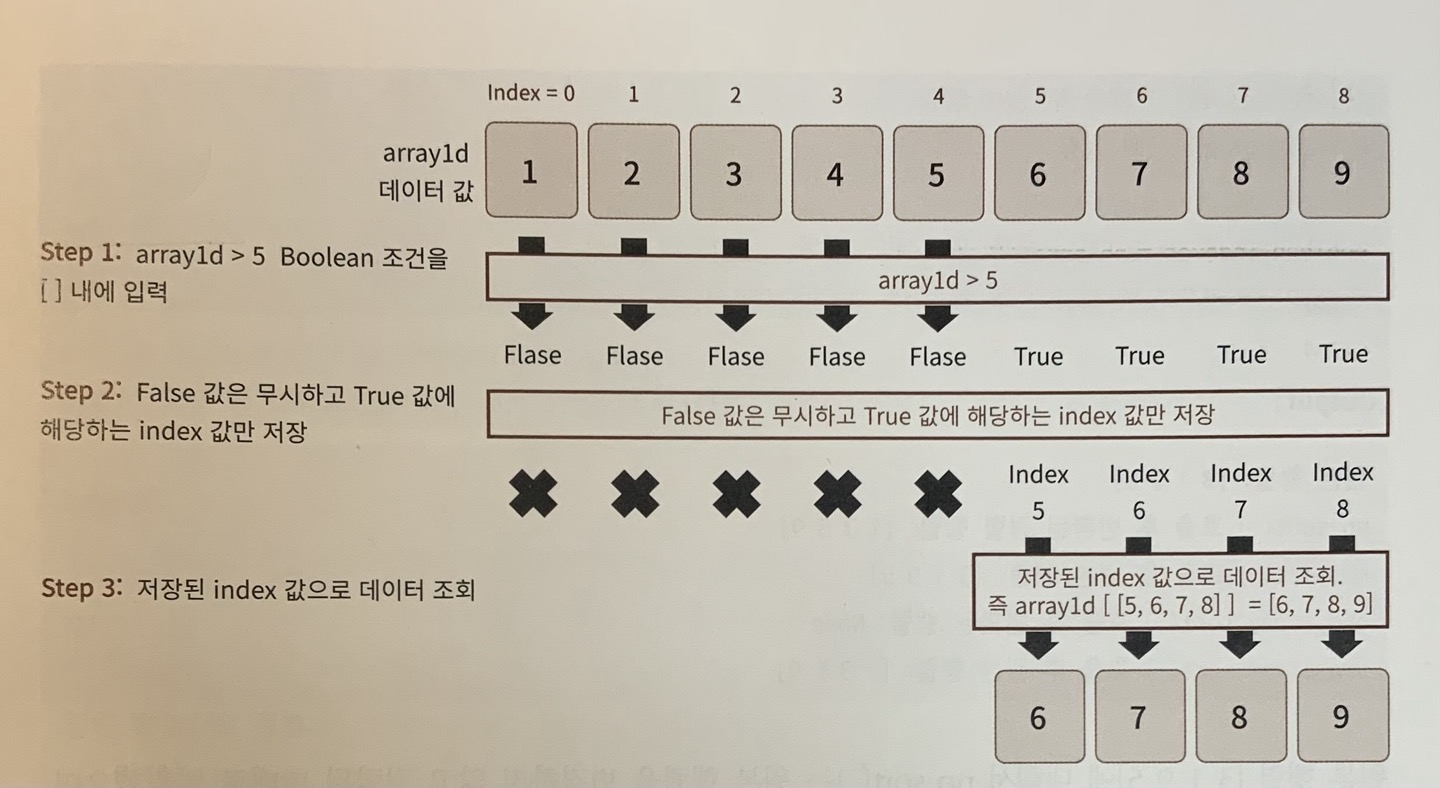
⏫불린 인덱싱이 동작하는 순서
step1) array1d > 5와 같이 ndarray의 필터링 조건을 [ ]안에 기재
step2) False값은 무시하고 True값에 해당하는 인덱스값만 저장
step3) 저장된 인덱스 데이터 세트로 ndarray 조회
참고)
파이썬 머신러닝 완벽 가이드, 권철민, 위키북스
'AI > 머신러닝' 카테고리의 다른 글
| [ML 실습] 4일차 복습- 판다스 DataFrame(1) (0) | 2025.01.28 |
|---|---|
| [ML 실습] 3일차 복습- 넘파이 마지막, 판다스 시작 (1) | 2025.01.27 |
| [LG AImers 6기] ML이론 - Bias and Variance (3) | 2025.01.23 |
| [LG AImers 6기] ML이론 - Introduction to ML (3) | 2025.01.21 |
| [ML 실습] 1일차 복습- 넘파이 ndarray (2) | 2025.01.14 |



