
'll Hacker
[LG AImers 6기] ML이론 - Bias and Variance 본문
안녕하세요 aI에 관심 생긴지 한달되었습니다.
졸프를 하면서 ai모델을 만들어서 프로젝트 진행하는 바람에, 저는 ai 감자새^^키라서 성능좋은 ai모델을 만들고자
LG aimers 6기에 참여했습니다. 공부 목적이니까 틀려도 양해부탁드리고, 댓글에 좋은 말로 고칠 부분 적어주세요😉
항상 봐주셔서 감사합니다! 구독도 부탁드리고, 좋아요도...ㅎㅎㅎ
이전 내용 소개
이전 블로그에서는 머신러닝, 딥러닝 그중에서도 머신러닝에 대한 개괄적인 설명을 했습니다.
https://successing.tistory.com/101
[LG AImers 6기] ML이론 - Introduction to ML
안녕하세요 aI에 관심 생긴지 한달되었습니다.졸프를 하면서 ai모델을 만들어서 프로젝트 진행하는 바람에, 저는 ai 감자새^^키라서 성능좋은 ai모델을 만들고자 LG aimers 6기에 참여했습니다. 공부
successing.tistory.com
이전 블로그를 안보신 분들은 위 링크타고 들어가셔서 보시면 됩니다!
이번 내용은 Bias and Variance에 대해서 설명해보고자 합니다.
Bias는 편향을 의미하고, Variance는 분산이라는 것을 사전을 통해 알고 계실 것입니다.
이것들은 기계학습의 오차를 나타내고, Trade-off 관계가 중요합니다.
Bias & Variance
Definitions of ML
그럼 구체적인 설명을 해보겠습니다.
학습 데이터가 n개가 있을때, Input 데이터는 Multi demesion인 vector 형태일 것입니다.
그럼 notation부터 제시하겠습니다.
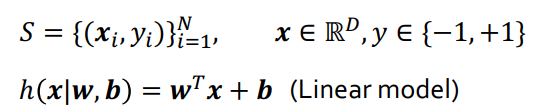
Xi는 input이고, Yi는 ouput입니다. 해당 조건에서 y의 범위는 -1~+1입니다. Classification에 활용하기 위함입니다.
h는 예측값입니다. 우리는 S 집합에서 학습데이터가 잘 동작하는 w, b를 찾는게 목표로 둬야 합니다.
제일 먼저 Model Class를 정의해야합니다 (ex: Linear Model) 그러면, 학습을 통해 값을 얻은 파라미터값이 나옵니다.
그렇다면 "잘 동작한다" 라는게 무엇일까요? 이것은 Loss Function을 사용하여 잘 동작함을 나타낼 수 있습니다.
Loss Function은 주어진 Input에 대해서 Model이 예측한 예측값과 Input에 대한 정답값이 틀리면 틀릴수록 큰 값을 주는 함수를 말합니다. 최종적으로 이 Loss Function을 최소화하는 w, b를 찾아야된다는 것입니다.

기계학습 알고리즘의 능력은 새로운 데이터를 정확하게 학습이 가능한가는 Overfitting과 연결지어서 설명할 수 있을 것입니다.

overfitting 함수는 되게 복잡하고 다차원형태로 표현을 합니다. Overfitting 상태라는 것은 너무 정확하게 학습데이터들을 하나하나 학습하려고 과하게 학습된 상태입니다. 이렇게 되면 학습데이터 이외 데이터는 잘 작동하지 않습니다.
반면 Generalization은 overfitting함수와 달리 부드러운 형태입니다. Training Error를 높아지지만, 즉, 정확도는 희생하지만 새로운 데이터에 대한 학습능력은 높아지게 됩니다.
관측이 불가능한 Universal Set이 있다고 가정한다면,
샘플링 10000개를 training set으로 하고, 아예 다른 샘플링 10000개를 test set으로 합니다. test set은 traing set에서 보지 못한 데이터이어야 합니다. Data를 얻는 과정이 서로 독립적이고, 샘플링하는 분포가 일정하다라고 하면 Universal set에 대한 분포 P(x, y)가 생성됩니다.
우리는 보지 못한 경우에 대해서 Expected Loss라고 말할 수 있습니다. 이때 Generalization Error을 계산할 수 있습니다.
Generalization error란, 기계학습 및 통계적 학습이론의 지도학습에서 일반화 오차 또는 표본 외 오차는 알고리즘이 전례가 없는 데이터에 대한 결과값을 얼마나 정확하게 예측할 수 있는지의 정도를 말합니다.
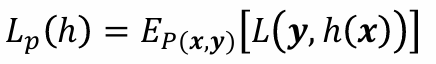
모든 경우에서 Loss를 예측하여, 정도를 파악하는 Notation입니다.
E는 Expectation으로 어떤 분포를 가지는 값을 우리가 하나의 숫자로 요약하겠다는 것입니다.
그래서 Loss를 하나의 숫자로 요약하여 어떤 확률 분포를 따르는데, x와 y가 true Distribution을 따른다고 하면 그 때 구한 loss의 평균값 혹은 기댓값을 구할 수 있습니다.
새로운 데이터에 대한 오류보다 정답이 있는 데이터의 오류가 더 크다면 Underfitting이라고 볼 수있고,
반대라면, Overfitting이라고 볼 수 있습니다.
Underfitting vs Overfitting?
underfitting이 더 안좋다고 합니다. 왜냐하면 학습을 제대로 못시켜서 이런 현상이 나타났다고 생각하기 때문입니다.
Traing an ML algorithm well
- overfitting시키기
Training error는 작은데 validation error와 차이가 큰 경우 Regularization 방식 활용한다. - 과도한 Overfitting 낮추기
Model's Capacity


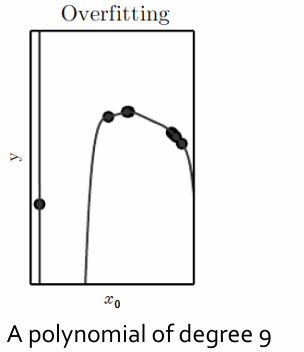
위 그래프처럼 각 상태에 따른 모델을 보시다시피
Overfitting 같은 경우 Data없는 구간이 심하게 굴곡이 나기 때문에 보지 못한 영역에서 updown현상이 발생합니다.
Occam's Razor에 이론에 따르면, "간단한 것이 좋다"라고 말합니다.

나무 뒤에 상자는 몇개인지 예측해보자면, 경우의 수는 다양합니다. 하나의 상자가 있을 수 있고, 두개의 상자가 있을수도 있습니다. 확인하기 전까지는 상자의 개수를 알 수 없습니다.
이처럼 여러가지 우연이 맞아야 하기 때문에 확률적으로 낮을 수 밖에 없기 때문입니다.
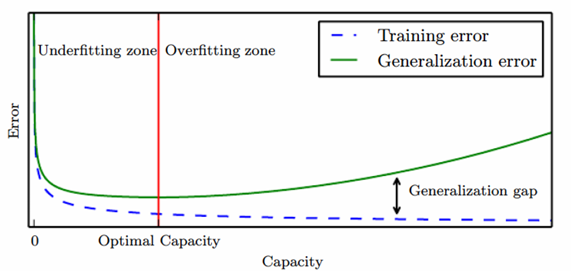
capacity가 증가하면 training error는 감소하게 됩니다. 그럼 이 차이가 커지게 되는데 이 차이가 최소화되는 optimal Capacity를 찾아야합니다. 그러기 위해 학습과정에서 Cross Validation 방식을 사용하여 Generalization error을 예측하여 Optimal Capacity를 찾습니다.
Regularization
Generalization error을 낮추기 위해 Regularization(정규화) 방식을 사용합니다.
우리의 데이터가 많은 경우 목적함수를 정의합니다. 우리가 학습과정 동안에 최적화 문제를 해결하기 위한 수단으로, 목적함수는 학습 Data에 대한 Loss Function을 정리해서 Loss가 최소화되도록 정의합니다.

Training Loss가 최소화되는 w를 찾습니다. Training Loss만 생각해서 하면 Overfitting가 되기 때문에 Regularization Term을 추가해야됩니다. 그러면, Loss만 최소화될뿐만 아니라, Model의 capacity도 최소화됩니다.
Bias / Variance Decomposition
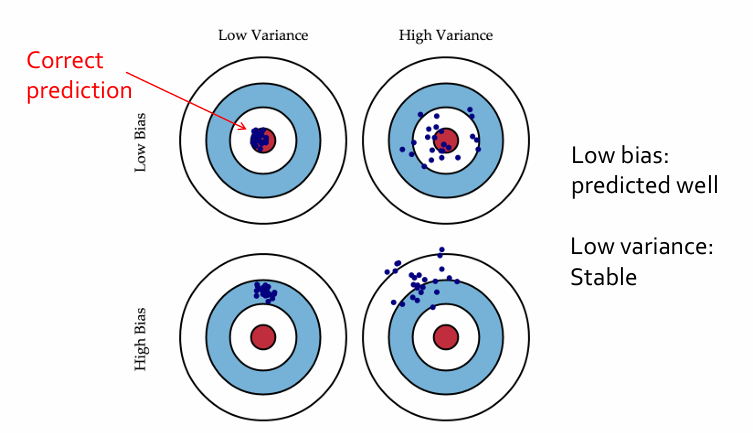
20개 예측값의 평균값과 실제 정답값의 차이를 Bias라고 하고, 20번 쏜 것의 평균값과 각 쏜 것과 거리를 다 제곱한 값에 대한 평균을 Variance라고 합니다. Low Bias - High Variance는 영점은 맞았지만 널뛰는 경우를 나타냅니다. High Bias - Low Variance는 안정적으로 쐈지만 영점이 안 맞은 경우를 나타냅니다. High Bias - High Variance는 영점도 안맞고 널뛰는 경우를 나타냅니다. Low Bias - Low Variance는 영점도 맞고 안정적으로 쏜 경우를 나타냅니다. 결국, Bias도 낮아야하고, Variance도 낮아야함을 의미합니다. 머신 러닝의 모델이 학습 상태를 알고, 최적의 모델을 찾기 위해 Bias와 Variance를 중요시해야합니다. 하지만 Bias가 높아지면 Variance를 낮아지게 되고, Bias가 낮아지면 Variance가 높아지게 되는 Trade-Off관계가 되는데 둘 다 낮출려면 Ensemble Learning 방식을 사용해야합니다.
Variance가 높아지게 되면 Overfitting이 발생하게 됩니다.(널뛰는 경우)
Bias가 높아지게 되면 Underfitting이 발생합니다. (정확하지 않은 경우)
여기까지 Bias와 Variance에 대한 설명이었습니다. 다음 내용은 Large Language Model에 대한 설명으로 돌아오겠습니다!
감사합니다!
참고:
서울대학교 김건희 교수님 강의자료
'AI > 머신러닝' 카테고리의 다른 글
| [ML 실습] 4일차 복습- 판다스 DataFrame(1) (0) | 2025.01.28 |
|---|---|
| [ML 실습] 3일차 복습- 넘파이 마지막, 판다스 시작 (1) | 2025.01.27 |
| [LG AImers 6기] ML이론 - Introduction to ML (3) | 2025.01.21 |
| [ML 실습] 2일차 복습- 넘파이 ndarray 인덱싱 (0) | 2025.01.18 |
| [ML 실습] 1일차 복습- 넘파이 ndarray (2) | 2025.01.14 |



